




DALL-E 3 now available in Bing Chat and Bing.com/create, for free!
We’re excited to share that DALL-E 3, the latest and most capable text-to-image model from OpenAI, is now generally available to everyone within Bing Chat and Bing.com/create—for free!

A new wave of innovation in Bing Chat and SwiftKey
Yesterday, Microsoft held an event in New York where we announced a broad set of news from across the company. I was honored to represent the latest innovations coming soon to Bing, Edge, and Microsoft Shopping. Today, we’re sharing more details on these announcements along with new feature updates to AI-powered SwiftKey.

Announcing Microsoft 365 Copilot general availability and Microsoft 365 Chat
Today at an event in New York, we announced our vision for Microsoft Copilot—a digital companion for your whole life—that will create a single Copilot user experience across Bing, Edge, Microsoft 365, and Windows. As a first step toward realizing this vision, we’re unveiling a new visual identity—the Copilot icon—and creating a consistent user experience that will start to roll out across all our Copilots, first in Windows on September 26 and then in Microsoft 365 Copilot when it is generally available for enterprise customers on November 1.
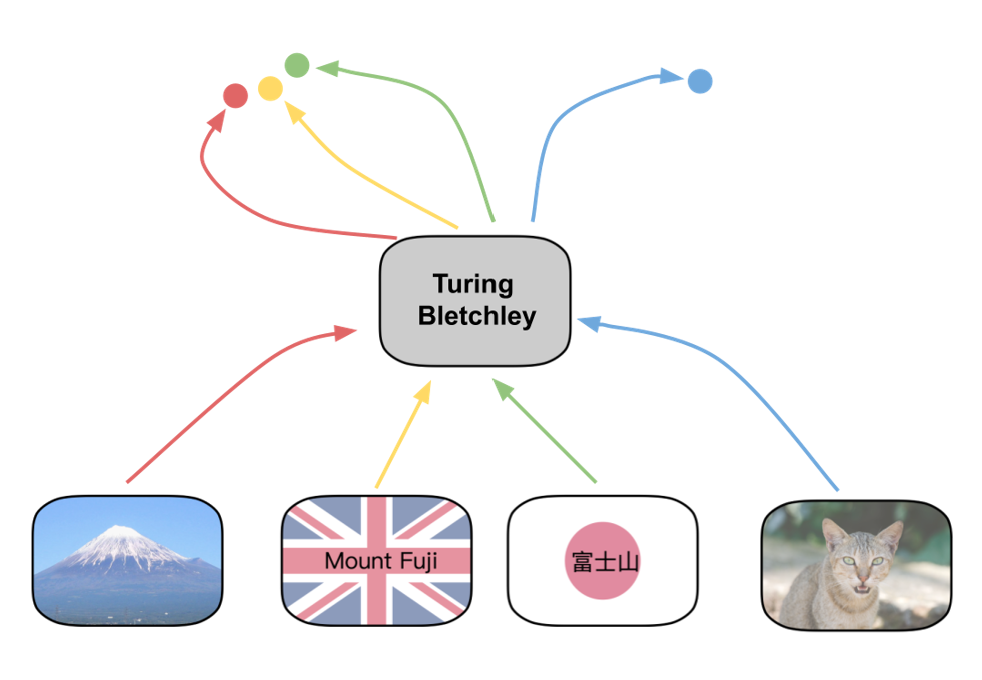
Turing Bletchley v3 - A Vision-Language Foundation Model
Today, the Turing team is excited to go into detail on how Turing Bletchley v3, a new multilingual vision-language foundation model, is used across Microsoft products. This model is the latest version of Turing Bletchley – our series of multilingual multimodal foundation models which understand more than 90 languages.

Celebrating 6 months of the new AI-powered Bing
It’s been six months since we reinvented search with the new AI-powered Bing and Edge. In that short time, you’ve engaged in so many unique and creative ways; to date we’ve seen over 1 billion chats and over 750 million images fill the world of Bing! We’ve also seen nine consecutive quarters of growth on Edge, meaning we’re more able than ever to bring our best-in-class AI experiences to users across the web.

Bing at Microsoft Build 2023: Continuing the Transformation of Search
A little more than 100 days ago, Microsoft introduced the world to your copilot for the Web with a new AI-powered Bing and Edge, beginning the transformation of the largest software category in the world—search. We’ve seen great progress in that short time, with people now doing things they couldn’t do with traditional search engines to be more productive and creative. Bing users have engaged in more than half a billion chats, created more than 200 million images with Bing Image Creator, while daily downloads of the Bing mobile app have increased 8x since launch.

Create Images with Your Words – Bing Image Creator Comes to the new Bing
Last month we introduced the new AI-powered Bing and Microsoft Edge, your copilot for the web, delivering better search, complete answers, a new chat experience and the ability to create content. Already, we have seen that chat is reinventing how people search with more than 100 million chats to date. Today we’re taking the chat experience to the next level by making the new Bing more visual.

Introducing the new Bing in Windows 11
Today, Microsoft announced a significant update to Windows 11, featuring an array of features that harness the power of AI and improve the way people get things done on their PC. The Bing team is thrilled to share that as a part of this update, we’re bringing the new Bing directly to the Windows taskbar, unlocking more ways to interact with your PC across search, answers, chat, and creation.
Reinventing search with a new AI-powered Microsoft Bing and Edge, your copilot for the web
To empower people to unlock the joy of discovery, feel the wonder of creation and better harness the world’s knowledge, today we’re improving how the world benefits from the web by reinventing the tools billions of people use every day, the search engine and the browser.

Microsoft Turing Academic Program Workshop
MS-TAP program has given a special opportunity to academics to research on Turing Language Model family with Microsoft. The workshop is to bring together the research institutions who participated in the program for the last 2 years to exchange their findings and learnings on their research on Large Language Models. We will also discuss the best way to make AI models by Microsoft more accessible to academics in a more accountable and responsible way so that we develop the foundational research community to drive the state-of-the-art of research and the innovation on Large Language Models together.
Turing Bletchley: A Universal Image Language Representation model by Microsoft
Today, the Microsoft Turing team is thrilled to introduce Turing Bletchley, a 2.5-billion parameter Universal Image Language Representation model (T-UILR) that can perform image-language tasks in 94 languages. T-Bletchley has an image encoder and a universal language encoder that vectorize input image and text respectively so that semantically similar images and texts align with each other. This model shows uniquely powerful capabilities and a groundbreaking advancement in image language understanding.

Microsoft Turing Universal Language Representation model, T-ULRv6, tops both XTREME and GLUE leaderboards with a single model
Today, we are thrilled to announce that the most recent addition to our Turing Universal Language Representation Model family (T-ULRv6) has achieved the 1st position on both the Google XTREME and GLUE leaderboards, demonstrating that a single multilingual model can achieve state-of-the-art capabilities in both English and Multilingual understanding tasks.

Introducing Turing Image Super Resolution: AI powered image enhancements for Microsoft Edge and Bing Maps
We can all probably think of a time when we had the perfect image - a prized portrait of a family member to be framed or the best screenshot to illustrate your point in a presentation - but could not use it because the quality was too low. Using the power of Deep Learning, the Microsoft Turing team has built a new model to help in these scenarios.
Scaling Up Multilingual Evaluation Workshop
Massively Multilingual Language Models (MMLMs) are trained on around 100 languages of the world, however, most existing multilingual NLP benchmarks provide evaluation data in only a handful of these languages. The languages present in evaluation benchmarks are usually high-resource and largely belong to the Indo-European language family. This makes current multilingual evaluation unreliable and does not provide a full picture of the performance of MMLMs across the linguistic landscape.

Microsoft Turing Universal Language Representation model, T-ULRv5, tops XTREME leaderboard and trains 100x faster
Our latest Turing universal language representation model (T-ULRv5), a Microsoft-created model is once again the state of the art and at the top of the Google XTREME public leaderboard..
Inside Microsoft's Project Turing, the team that's quietly reinventing how it develops advanced AI to move faster and take on rivals like Google
Since 2017, Microsoft has pursued this goal under the name Project Turing, a team that's tasked with building these large language models and figuring out how they can be used in the company's vast suite of products.
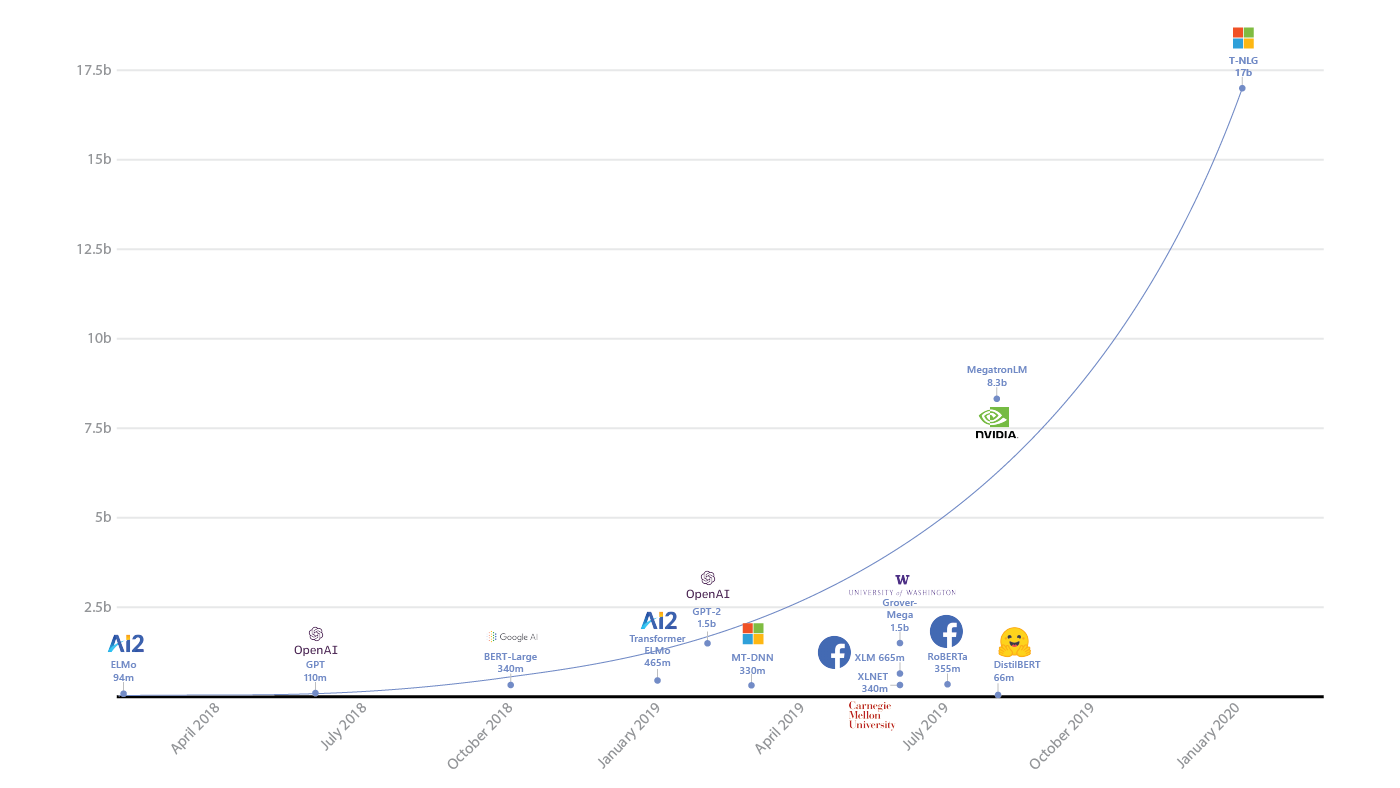
Microsoft Turing-NLG: A 17-billion-parameter language model by Microsoft
Turing Natural Language Generation (T-NLG) is a 17 billion parameter language model by Microsoft that outperforms the state of the art on many downstream NLP tasks. We present a demo of the model, including its freeform generation, question answering, and summarization capabilities, to academics for feedback and research purposes

Generate Chatbot training data with QBox — powered by Microsoft Turing NLG
One of the primary challenges when building any kind of chatbot is producing or obtaining high-quality, diversified training data. The training data that you use across your model’s intents will determine how readily your model picks up on a real user’s true intent when exposed to queries it’s never seen before. So no matter what chatbot framework you’re using (e.g. Microsoft LUIS, IBM Watson, etc.), having high-quality training data is a must..

Microsoft trains world’s largest Transformer language model
Microsoft AI & Research today shared what it calls the largest Transformer-based language generation model ever and open-sourced a deep learning library named DeepSpeed to make distributed training of large models easier.
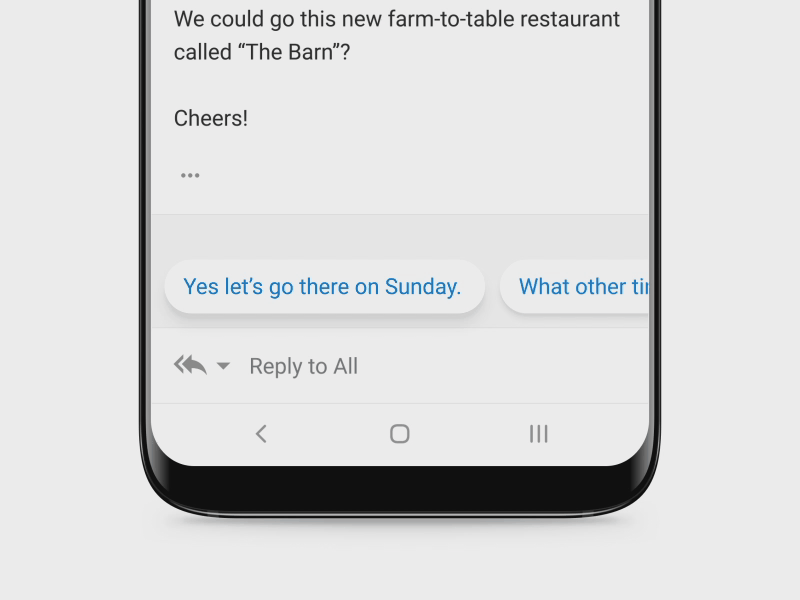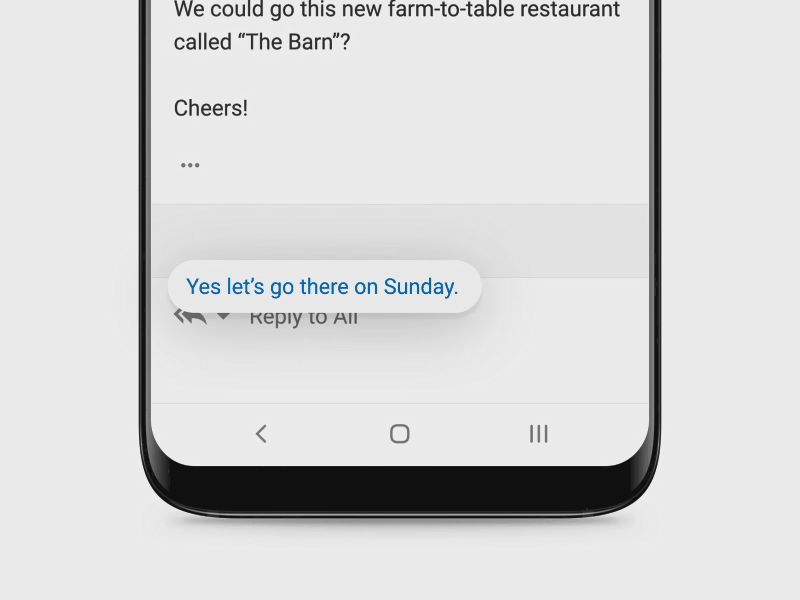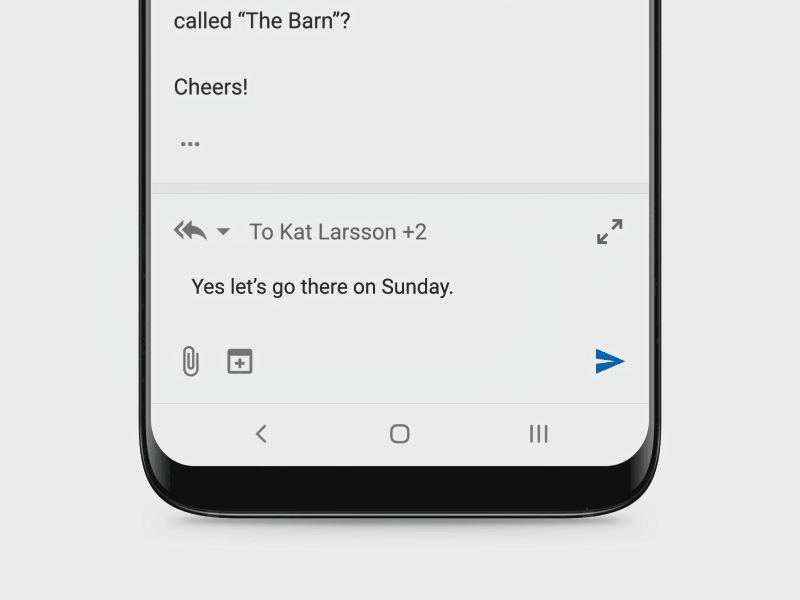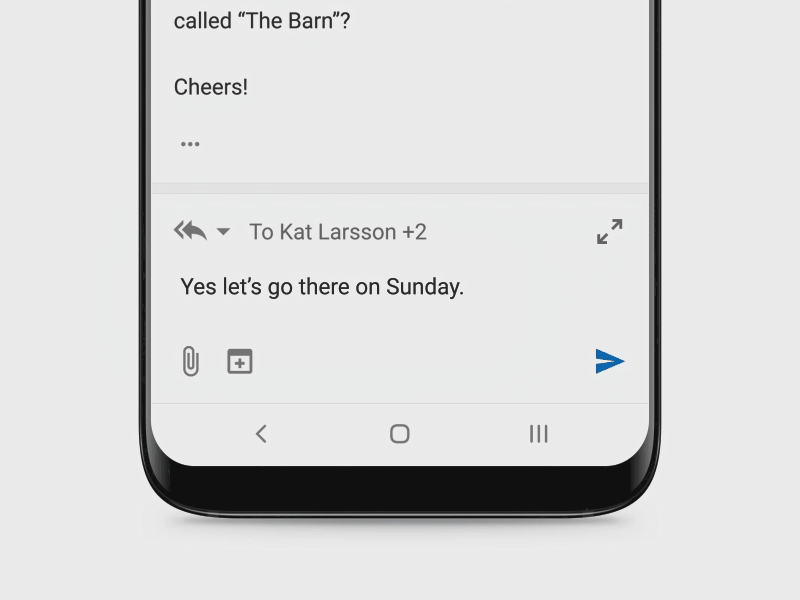
Assistive AI Makes Replying Easier – Microsoft Research
Microsoft’s mission is to empower every person and organization to achieve more. So, we are constantly looking for opportunities to simplify workflows and save people time and effort. Sending replies to email or chat messages is a common activity and people spend considerable amount of time on it.

Careers
Want to make a difference? So do we! Step in to explore the wealth of career opportunities and take your career to the next level.
CONTACT US